Your Data on Point
Datapunctum is your partner for analysis and reporting of all your IT operations, security and business data at scale.
Data Analytics
Turn Data into Decisions
Advisory Services
We provide strategic guidance to navigate complex challenges and achieve your goals.
Professional Services
We turn your data into actionable insights and streamline operations with expert solutions.
Security Services
We safeguard your business with robust, proactive security solutions tailored to your needs.
The Market's Best Splunk Apps
Discover our Premium Splunk Apps for IT Security and IT Ops
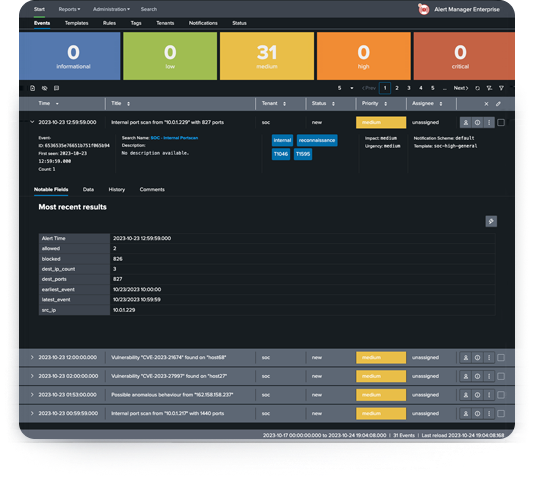
Alert Manager Enterprise
The most powerful alert management solution for Splunk. Turn alerts into actionable, context-rich incidents.
Industries We Serve
Delivering data-driven solutions across sectors
Our Customers & Partners
Trusted by leading organizations worldwide




Latest from our Blog
Stay up to date with our latest news, product updates and insights

Alert Manager Enterprise for Electric Utilities: Simplifying NERC CIP Compliance Inside Splunk
This article explains how Alert Manager Enterprise (AME) helps grid operators meet NERC CIP requirements without leaving their secure Splunk environment.

AME Release: 3.8
AME 3.8.0 brings custom email subjects, template-powered manual events, Microsoft Defender vuln ingestion, path-based reverse proxy support, expanded vuln KPIs — and important fixes.
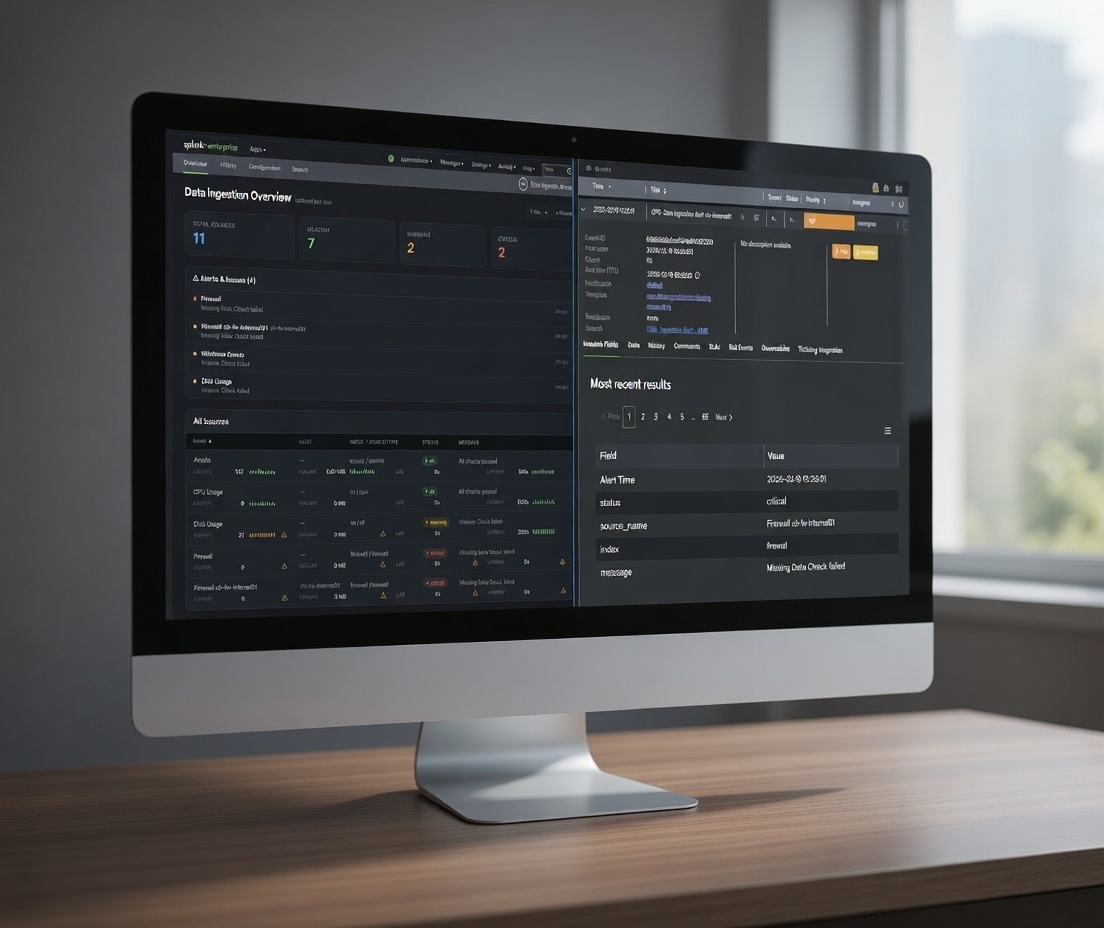
Use Case: Data Ingestion Monitoring with AME
Data ingestion failures often go unnoticed until it's too late. In this post, we share how a simple detection layer + Alert Manager Enterprise monitors ingestion health.
Ready to Tackle Your Data Challenges?
From security threats to complex analytics, we're here to turn your data challenges into opportunities.